January 5, 2022
Limitations of Salesforce Duplicate Management Tools
9 obstacles you may run into when using Salesforce’s native deduplication tools and how to overcome them

Are you underwhelmed by Salesforce’s native duplicate management tools?
Yikes, that sentence was dull. Let’s try it again.
Are you completely baffled by the fact that there’s no way in Salesforce to simply click a button, see all the duplicate records in your org, merge them in mass, and not have to worry about dupes anymore?
While there are ways to find and merge duplicates natively in Salesforce, the process is not perfect. It requires a lot of time, resources, and comes with limitations.
Before we begin, let’s set the roadmap for what we’ll focus on in this article.
Basics of Duplicate Management
Achieving and maintaining high data quality is a two-prong approach. It’s important to both
- prevent duplicate records from entering your org at the point of entry, as well as,
- eliminate any existing dupes that are already in your org. Salesforce does have ways to do both of these things – prevent and eliminate duplicate records – but the methods are not ideal.
In this article we’ll focus on how to find and merge duplicate records that already exist in Salesforce using out-of-the-box tools and what you need to watch out for. In other words, how to clean up your Salesforce records while also keeping in mind what you may be missing.
To prevent duplicate records, check out Salesforce’s duplicate rules functionality or download a free dupe blocker on the Salesforce AppExchange.
Where Salesforce's built-in dedupe tool options fall flat
While Salesforce's native deduplication tools do provide some power, for most orgs, especially larger companies with thousands or millions of records, managing duplicates can be very cumbersome if done with the built-in tools alone. And these limitations could cause a lot of duplicates to slip through the cracks.
We’ve identified nine obstacles you may run into using Salesforce’s native data management functionality:
1. Finding and merging duplicates cannot be done in mass or automatically
Salesforce comes with a few different ways to identify duplicate records, depending on whether you use Classic or Lightning. But no matter which method you use, the biggest downside is that it’s all a manual process.
Salesforce Classic - In find and merge duplicates in Salesforce Classic, you can only do so on a per-record basis by drilling into the record itself. For example,
- To find duplicate Leads, you must select the “Find Duplicates” button on any lead record page.
- Identifying potential Contact dupes is done by selecting the “Merge Contacts” button on an Account page (not on a Contact record page).
- Duplicate Accounts are found by selecting “Merge Accounts” at the bottom of the Accounts home tab. From there, you must search for individual Account names to find potential duplicates.
Salesforce Lightning - The process is the similar: you can see potential duplicate matches when actively viewing an individual Lead, Contact, or Account record using the “Potential duplicates” competent.
In either Classic or Lightning, you must open and review each individual duplicate group to merge the matching records.
Salesforce Duplicate Jobs
A somewhat better alternative is to use Duplicate Jobs to find duplicates globally throughout your entire org. This module acts as a report and scans your records to find duplicates that match based on matching rules. What’s good about this option is that you can customize the matching rules, but the rules themselves do have their own restrictions (see #2 below).
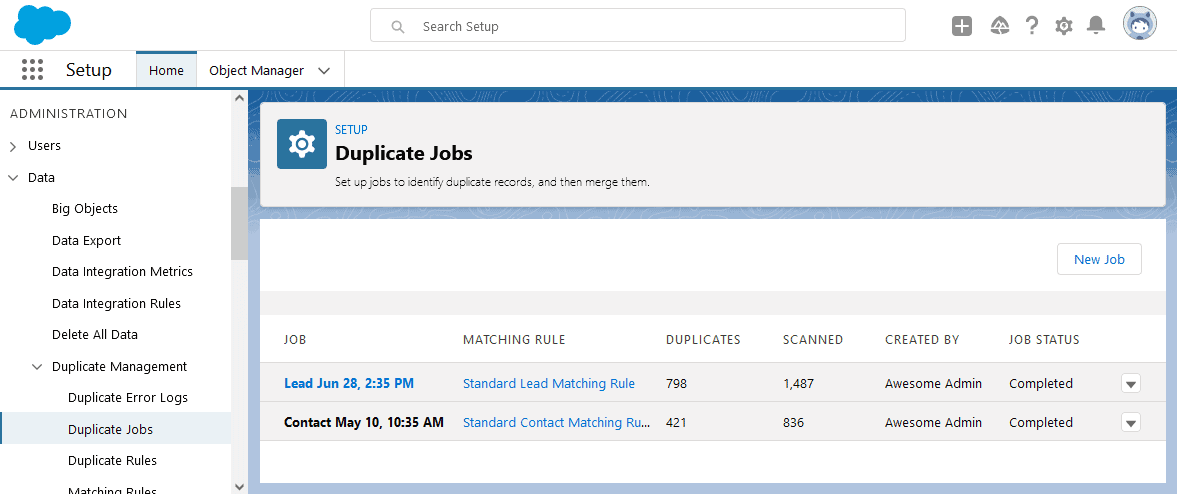
After a duplicate job has run, you’re presented with groups of duplicates which you can then review and manually merge. Again, compromises arise with this option (see #3, #5, #8, and #9 below).
Lately, you can also run a custom report to see a list of duplicates. Once compiled, you can drill into records to manually merge them one at a time.
No matter which method you use to find duplicates, the ability to select multiple groups of duplicates or even schedule automatic deduping jobs is not possible with Salesforce’s built-in functionality. For orgs with large amounts of data, this deduplication method would take a tremendous amount of time.
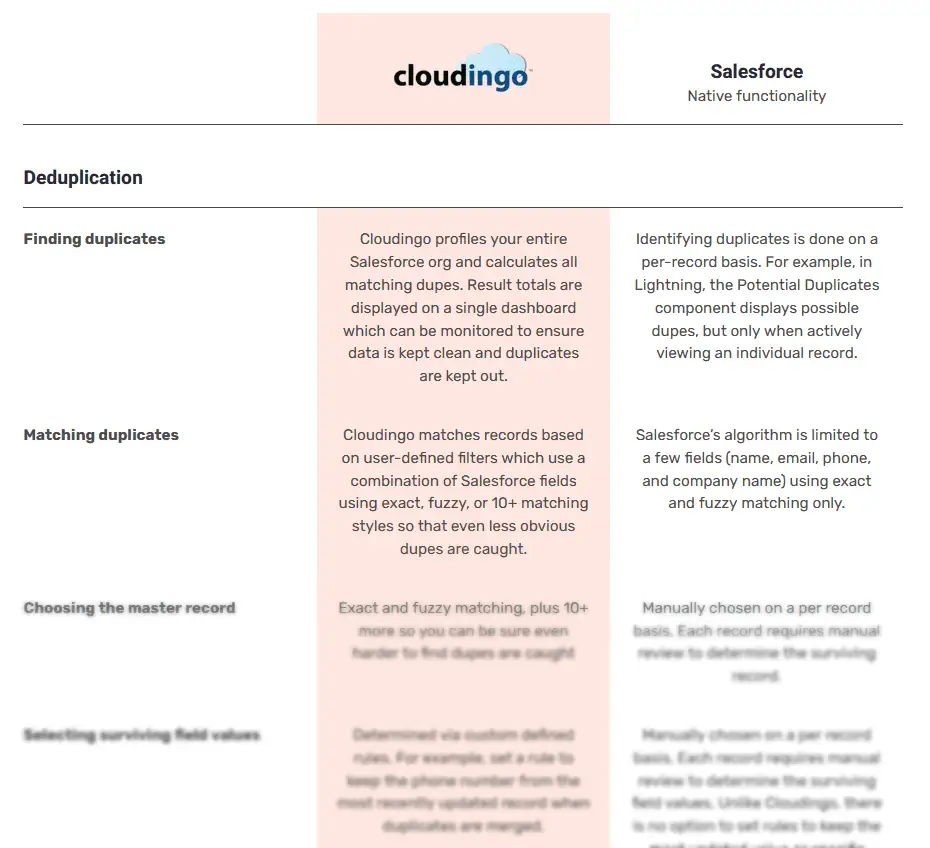
2. There are very few matching algorithms and options
How does Salesforce determine which records are duplicates?
By default, Salesforce’s duplicate algorithm is very simple and looks at just a few fields, like name, email address, phone, and company name with little variance, and uses exact or fuzzy matching. This can be fine to search for more obvious duplicates, but finding hidden dupes requires more sophistication.
You do have the option to create custom matching rules, but again, you are limited to exact and fuzzy matching.
3. Choosing the master record and field selections can be cumbersome
How does Salesforce determine which record is the master record? Can you choose which field values trump others?
When merging records, by default, Salesforce chooses the oldest record to be the retaining record, or the master record. You do have the option to manually pick another record to be the master, however. You can also pick and choose which field values carry over to the final record.
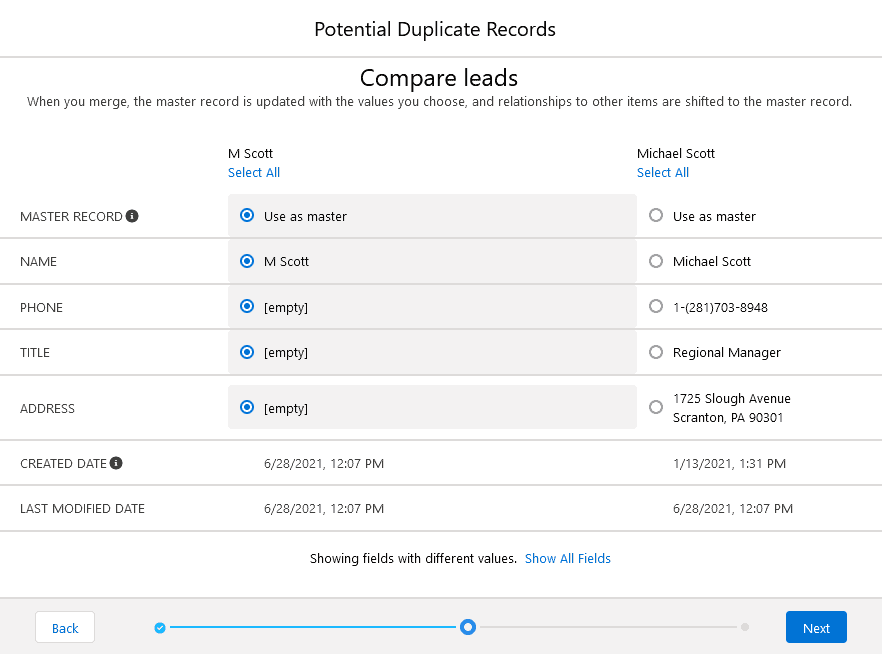
A problem occurs when presented with two duplicate records with different field values.
For example, suppose you have duplicates each with different phone numbers. By default, the phone number on the oldest record will be carried over. But wouldn’t you prefer to have the most updated phone number? Although you can pick and choose which phone number to keep, there is no way to visually know which phone number was last updated without drilling into each record.
Once again, this is all a manual process and cannot be done automatically on a scheduled basis, nor can you mass merge groups of duplicates at one time.
How do you merge Leads that are duplicates of existing Contacts?
If a Lead exists as both a Lead and a Contact, you can manually merge the Lead into the existing Contact on a per-record basis. This is done on the individual Lead page.
Unfortunately, you can’t convert Leads to existing Contacts using Salesforce’s duplicate jobs. In other words, the convenience of seeing a list of Leads that also exist as Contacts and merging them at one time is not possible.
Looking for a better way to manage duplicates?
See how to overcome the limitations of Salesforce's native data management tools with Cloudingo
4. You can only merge 3 records at a time
When viewing a group of duplicate records, you can only merge three records at a time. Any more than this and you’ll have to repeat the process until all duplicates have been merged into one final record.
5. There is no duplicate management for custom object
The Potential Duplicates component in Lightning cannot be added to custom objects, and there is no duplicate management option in Classic UI for custom objects.
Duplicate jobs can run on custom objects, but you can’t compare and merge these duplicates.
6. Duplicates are ignored when importing
Suppose you are given a list of Leads that need to be uploaded to Salesforce. How do you know if some of those Leads already exist in Salesforce?
Unfortunately, Salesforce's duplicate management tools do not look at records that are uploaded using native import tools. So take extra precautions to ensure your import list doesn't have duplicates within the file, and ensure that records don't already exist in Salesforce. Or use a mass import tool that compares your file against existing Salesforce records to ensure you don't upload any duplicates.
7. Not ideal for large organizations
Chances are if you have a large number of records in your Salesforce org, you also have a lot of duplicates. Because deduplication is a manual process in Salesforce, you can imagine how improbable cleaning up a large org could be without the help of more sophisticated deduping tools.
Native data management tools also have technical limitations for larger orgs. Salesforce states, “In an org with many records, duplicate jobs can fail.” How many records this applies to is not mentioned.
8. Biggest limitation: it's very time-intensive
Because finding and merging duplicates is done on a record-by-record basis natively in Salesforce, it would require a tremendous amount of time and resources to clean up your entire Salesforce org.
Finding duplicates natively in Salesforce relies on a lot of luck, by just surfing onto an individual record. Further, getting rid of those duplicates involves a lot of clicking, navigating, screen hopping, decision-making, and hoping your users have the time and patience to deal with the problem. Imagine the time and manpower required for organizations with thousands or millions of records.
Is there a better alternative to Salesforce's native data management tools?
One of the best aspects of Salesforce is the ability for third-parties to fill in gaps where the CRM technology falls short.
In 2011, being frustrated Salesforce users ourselves and tired of the tedious process of data cleansing described above, we created Cloudingo – a cloud-based data cleansing platform.
We built Cloudingo to overcome the limitations of native deduping tools that are mentioned above.
For example, our users love the fact that you can create and run filters to find all the duplicates hiding in your org. Then you can merge them in mass, automatically, or manually if you prefer.
You can also dedupe custom objects and across objects, like Leads to Contacts. With Cloudingo you can also check for duplicates before importing to make sure you don't upload records that already exist in Salesforce.
So, if you're overworked and looking for a better way to manage duplicates, try Cloudingo free or request a demo.
Looking for a better way to manage duplicates?
See how to overcome the limitations of Salesforce's native data management tools with Cloudingo


